
The Google File System I
After finishing reading Professor Arpaci-Dusseau’s book Operating Systems - Three Easy Pieces recently, I decide to read this paper again.
Introduction
The Google File System (GSF) is a scalable distributed file system that consists of hundreds of storage machines (1000 storage nodes and over 300 TB of disk storage on 2003) and is accessed by a large number of clients.
Key Observations
- Componenent failure. This is common for distributed systems.
- Huge files of several GB are common, since many files are web documents containing many application objects.
- Most files are mutated by appending new data than overwriting existing data. Random writes within a file are rare. The files are often read sequentially once written. The first point is reasonable considering the nature of google docs, most operations should be to write to the google doc instead of replacing one document by a new one from the client’s local PC.
- Several clients can concurrently write to the same file and read through it simultaneously.
- High sustained bandwidth is more important than low latency.
- Co-design the applications and the file system API.
According to the observations, the workloads primarily consist of two kind of reads: large streaming reads of > 1 MB and small random reads of several KB. It also has many large and sequential appending. Once written, files are seldom modified again. Small random writes do not need to be efficient.
Interface
In addition to usual operations like create, delete, open, close, read and write, GFS also supports
- snapshot: Create a copy of a file or a directory tree at low cost.
- record append: Allow multiple clients to append data to the same file concurrently while garanteeing the atomiciy of each client’s append.
Architecture
A GFS consists of
- A single master that stores the files metadata and controls system-wide activities.
- Multiple chunkservers that save replicas of file chunks.
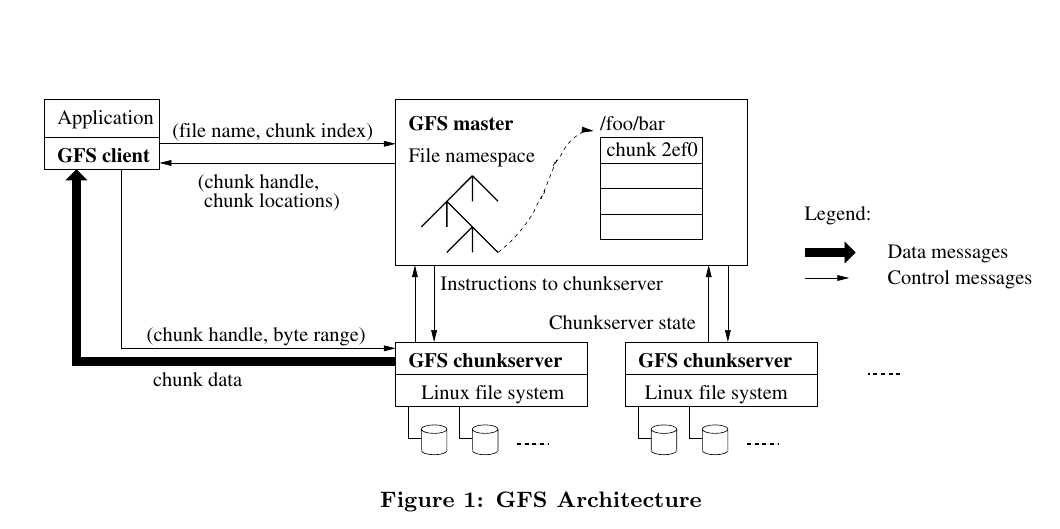
Files are stored as a collection of fixed-size chunks (64 MB on 2003). Each chunk is identified by an immutable and global 64 bit identifier called chunk handle. The chunk handler is assigned by the master at the time of chunk creation.
The workflow of a simple read is as following
| Client | Master | Chunkserver |
|---|---|---|
| Translate the filename and byteoffset for read into a file chunk index | ||
| Send the filename and file chunk index to master | ||
| Receive the request of filename and file chunk index | ||
| Send the chunk handle and replica locations to client | ||
| Receive chunk handle and replica locations | ||
| Cache these informations with filename and file chunk index | ||
| Send request of chunk handle to one chunkserver with replica | ||
| Receive chunk handle request | ||
| Send the corresponding chunk to client |
Metadata
There are three major types of metadata
- File and Chunk namespaces
- File to chunk mapping
- Chunk replicas’ locations
The metadata is stored in memory to assure performance.